Introduction
Welcome to a new article on my blog. Today I’m covering a topic that helps deepen your understanding of Kubernetes: the deployment of Large Language Models (LLMs) on Azure Kubernetes Services (AKS) running on Azure Local. I’ll explain some basic concepts along the way. If anything sounds unfamiliar, I recommend checking out my previous article: Azure Local: AKS and SQL Managed Instances.
Let me also apologize up front for the slight clickbait in the title. Because of my lab setup (a laptop with 64 GB of RAM, where Azure Local only gets 34 GB) I didn’t deploy an actual LLM, but a Small Language Model (SLM). The process and implementation are identical, though.
Infrastructure Design
Before deploying anything, we should review the resources we have available and come up with a plan. As mentioned, I only have my “Azure Local Lab” running fully virtualized on my laptop. Since I can’t use a GPU on AKS here and RAM is limited (around 20 GB free for AKS, shared between the control plane and the worker nodes), I designed a simple and lightweight proof of concept.
If I had the right hardware, I would have deployed KAITO (Kubernetes AI Toolchain Operator). But since I currently don’t have a GPU available, we’ll stick to my CPU-only variant. Still, here is the KAITO architecture for reference:
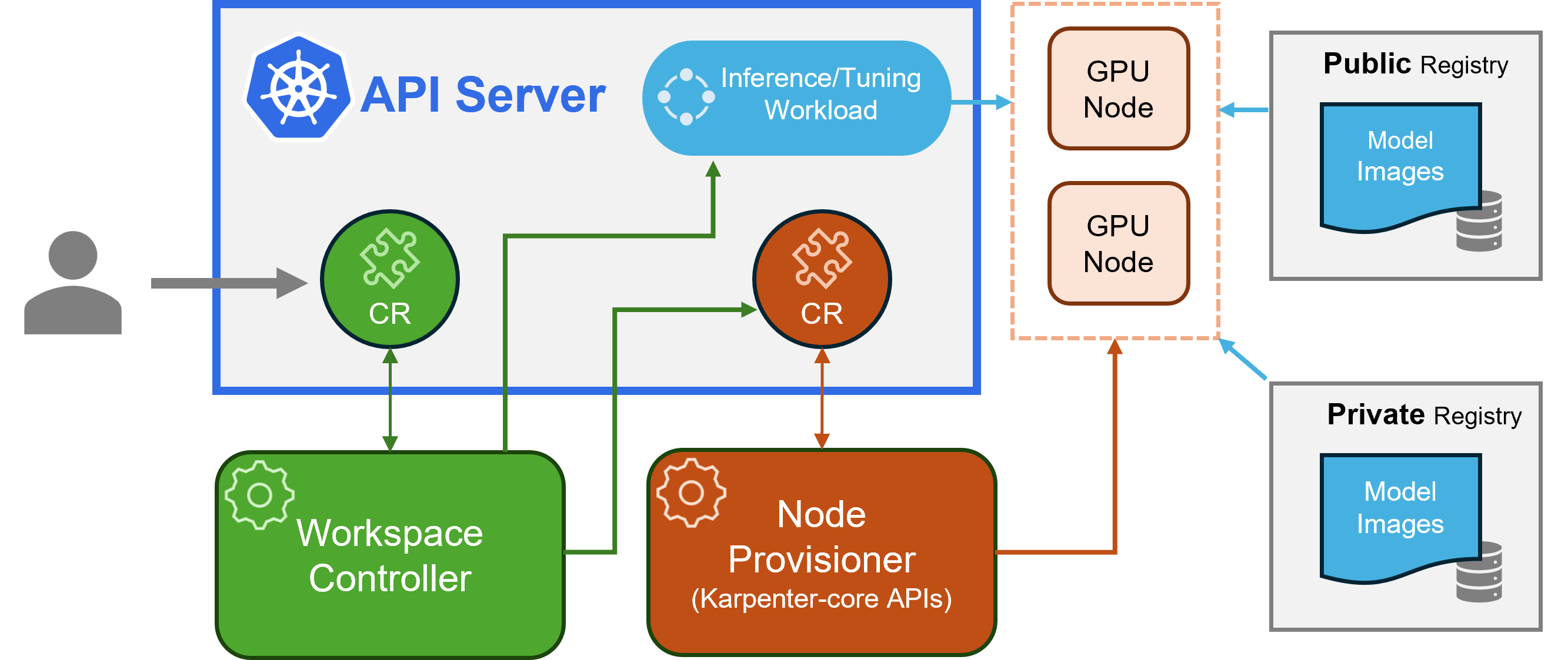
To make the architecture of my lab easier to understand, I prepared a diagram based on the one shown in the official Baseline Architecture for AKS on Azure Local.
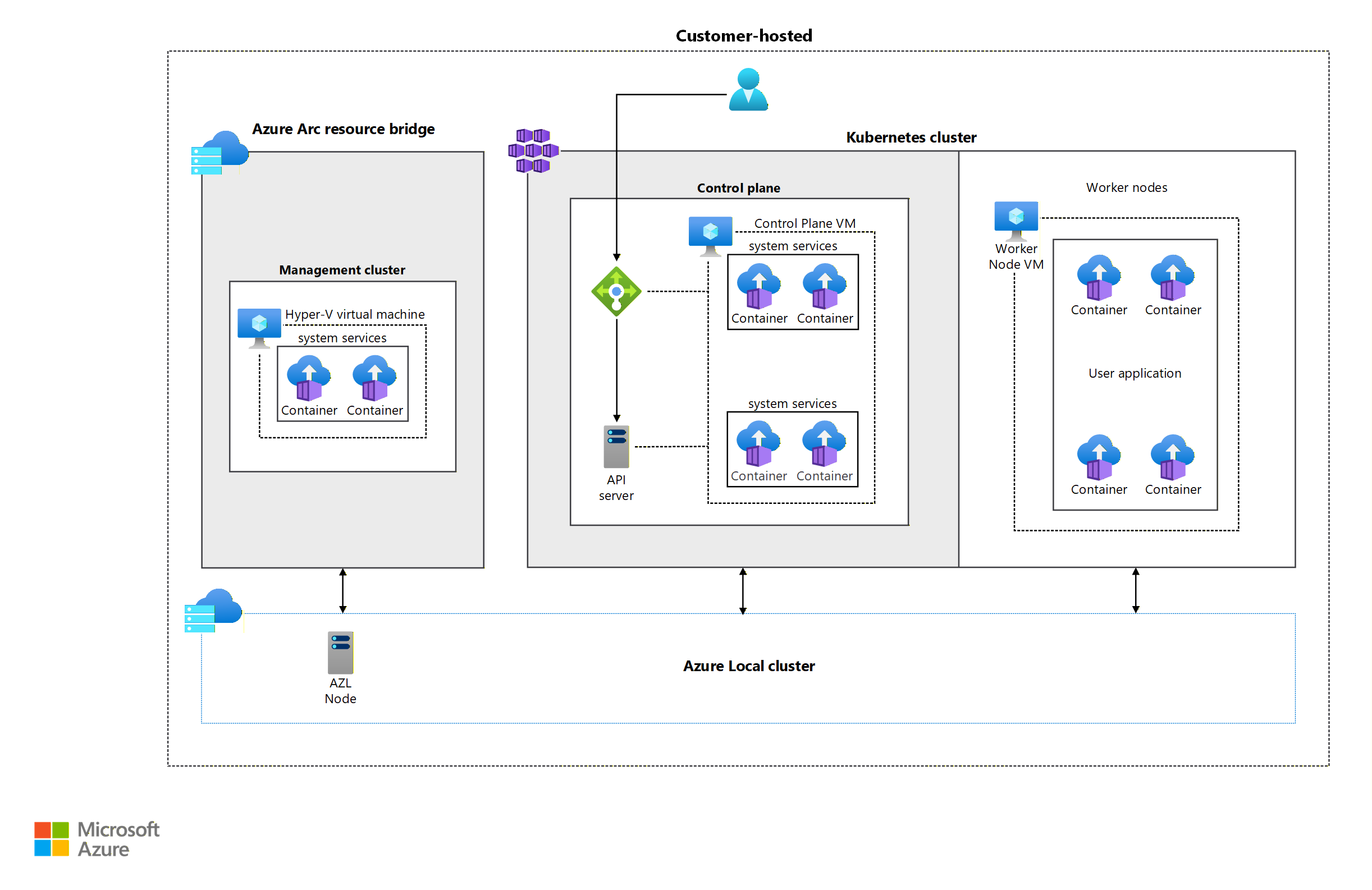
In the diagram you can see the components we’ll deploy:
- Azure Local: A single virtualized node that in turn hosts the nested AKS cluster
- AKS VMs:
- One control plane VM that acts as API server and LoadBalancer (via MetalLB)
- One worker node responsible for running the workloads
- Control plane size: Standard_K8S3_v1 (4 vCPUs, 6 GB RAM)
- Worker node size: Standard_A4_v2 (4 vCPUs, 8 GB RAM)
- Logical AKS infrastructure:
- A dedicated namespace for LLM-related workloads
- A single external IP from MetalLB (172.19.19.90) for Open WebUI
- Persistent storage of 25 Gi for Ollama to keep the model files between updates
This is the workload architecture inside AKS:
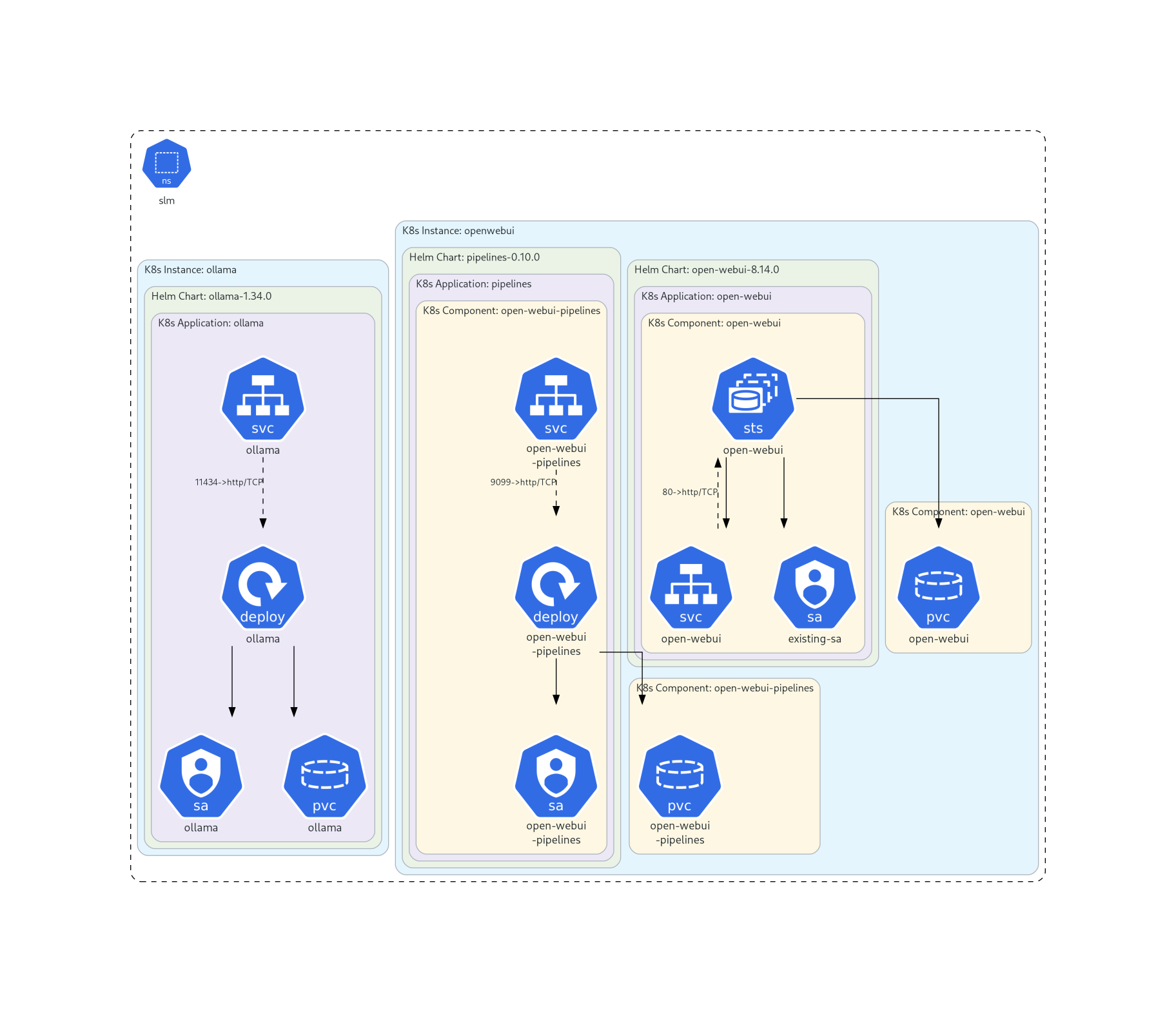
The whole deployment is carried out from my laptop, which has direct Layer 2 network access to the AKS cluster. I use Az CLI, kubectl and Helm. Throughout the process I’ll point out which tool is used and why. The goal here is to test LLM capabilities in this specific environment, not to deploy a standardized production-grade AKS hybrid application.
If you’re interested in the proper deployment approach for production AKS hybrid applications, I recommend reading:
Deploy and operate apps with AKS enabled by Azure Arc on Azure Local.
That article covers pipelines, GitOps, Flux, Helm and other components, giving you a great high-level overview of the possibilities.
Another option would be a hybrid model using self-hosted agents and a Service Bearer Token (which we’ll create later in this article under “Creating a Service Account to Manage AKS Locally”). This can give you more flexibility, though I personally recommend the GitOps approach.
With the architecture clear, let’s move on to implementation.
Requirements and Tool Installation
To deploy everything, you’ll need:
- A client machine (in my case the laptop running the lab) with direct network access to the AKS cluster running on Azure Local
- The following tools installed:
- Helm, for deploying workloads to AKS
- Az CLI with the aksarc module, to authenticate and retrieve local AKS credentials
- kubectl, to manage AKS directly
- An AKS cluster capable of running the workload (at least 8 GB RAM on the worker node) with temporary internet access during deployment
- The ability to add or modify local IP addresses used by the LoadBalancer (MetalLB)
Some of these requirements were already covered in the previous article, but let’s go through the ones that weren’t.
Modifying AKS
As mentioned, my lab runs nested on a laptop with 64 GB RAM, and Azure Local can only use around 36 GB or else the laptop becomes unusable. The Azure Arc Resource Bridge VM alone consumes 8 GB (or 16 GB during updates since another image is temporarily mounted). Azure Local itself uses between 4 and 8 GB depending on the moment. That leaves roughly 20 GB for AKS.
This memory has to be shared between the control plane and the worker nodes. To simplify the scenario, I limited the cluster to:
- One control plane with the minimum RAM → 6 GB
- One worker node with enough RAM to run Ollama and Open WebUI → 8 GB
I made these changes directly in the Azure Local portal under Settings > Node pools.
I also added the IP range 172.19.19.90–172.19.19.99 for MetalLB under Settings > Networking.
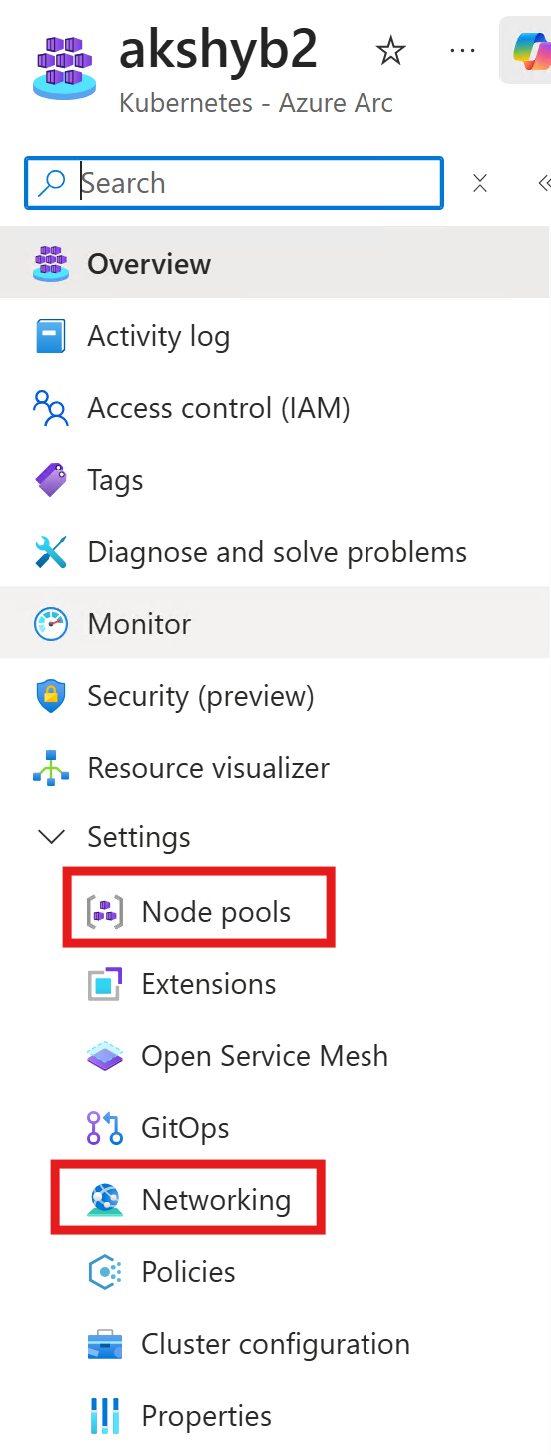
Once AKS is ready, we need a local management channel using a bearer token.
Creating a Service Account to Manage AKS Locally
I’ve needed bearer tokens long before AI workloads became trendy. In past projects I used them for self-hosted agents and even started a repository almost two years ago that covered this topic:
AKS Hybrid.
It’s a bit abandoned because I moved the more interesting content to other repositories.
The goal in this section is to access the AKS cluster locally. So I created this script:
12_AKSArcServiceToken.ps1
This script:
- Uses Az CLI and aksarc (installing the extension automatically if missing)
- Retrieves local AKS credentials
- Creates an admin user to manage the cluster
- Generates both a kubeconfig file and a txt file with the token
- Saves everything in the same directory
- Includes an extensive description
- Runs interactively if no parameters are provided
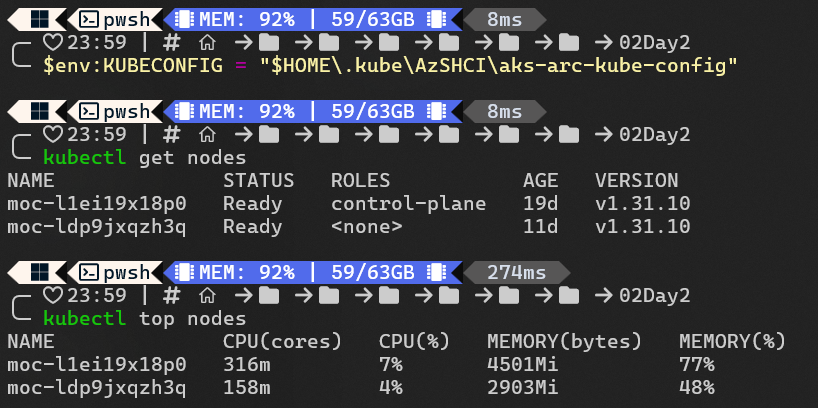
When the script finishes, set your kubeconfig environment variable:
$env:KUBECONFIG = "$HOME\.kube\AzSHCI\aks-arc-kube-config"
After that you can manage AKS directly with kubectl.
Now we can proceed with the workloads.
Installing Helm
We’ll use Helm to deploy the workloads. Helm is a package manager for Kubernetes. It lets you install and update complete applications using charts, which define deployments, services, volumes and configuration. In hybrid environments like AKS on Azure Local, Helm is extremely convenient because it helps you avoid writing raw YAML by hand and makes versioning and updates easier.
Install it using Winget:
winget install Helm.Helm
With Helm installed, we’re ready for the next part: deploying the LLM and exposing it on the local network.
LLM Deployment
Before going into commands, I want to explain why I chose Ollama as the base for the LLM. In a hybrid environment like AKS on Azure Local, you want something light, flexible and easy to operate. Ollama fits this perfectly. It’s one of the most popular inference engines in the community, offers a wide variety of ready-to-use models and is extremely simple to work with. It doesn’t require complex dependencies, starts quickly and lets you load models with a single command. This makes it ideal for demos, internal testing or small services running on limited hardware.
In this section we’ll deploy the full stack consisting of Ollama and Open WebUI inside the cluster. The goal is to maintain a simple, easy-to-manage architecture while still having the flexibility to run lightweight models in a controlled environment.
Below I explain each command step by step and what it means for the overall setup.
Create the namespace
kubectl create namespace slm
This creates a dedicated namespace called slm. It keeps all LLM-related components isolated, making it easier to manage, clean up or extend later.
Add Helm repositories
helm repo add otwld https://helm.otwld.com/
helm repo add open-webui https://helm.openwebui.com/
helm repo update
These are the official repositories for Ollama and Open WebUI.
Deploy Ollama as an internal service
helm install ollama otwld/ollama `
--namespace slm `
--set service.type=ClusterIP `
--set ollama.port=11434 `
--set persistentVolume.enabled=true `
--set persistentVolume.size=20Gi `
--set ollama.models.pull[0]=phi4-mini:latest `
--set ollama.models.run[0]=phi4-mini:latest `
--set resources.requests.cpu="2" `
--set resources.requests.memory="2Gi" `
--set resources.limits.cpu="4" `
--set resources.limits.memory="4Gi"
Key points:
- ClusterIP keeps the service internal
- Port 11434 is the default Ollama API port
- 20 Gi persistent volume ensures models don’t have to be re-downloaded
- phi4-mini:latest is pulled and launched automatically
- Resource requests and limits prevent the node from being overloaded
Check the pods:
kubectl get pods -n slm
Deploy Open WebUI as a LoadBalancer
helm install openwebui open-webui/open-webui `
--namespace slm `
--set service.type=LoadBalancer `
--set ollama.enabled=false `
--set ollamaUrls[0]="http://ollama.slm.svc.cluster.local:11434" `
--set persistence.enabled=true `
--set persistence.size=5Gi
Key points:
- Exposed via MetalLB
- Connects internally to Ollama
- 5 Gi persistence for settings and local data
- You can define a static IP by adding
--set loadBalancerIP=<your-ip>
Check pods again:
kubectl get pods -n slm
Final result
Retrieve the external IP:
kubectl get svc -n slm

You can now create an admin user and start using the deployed LLM:
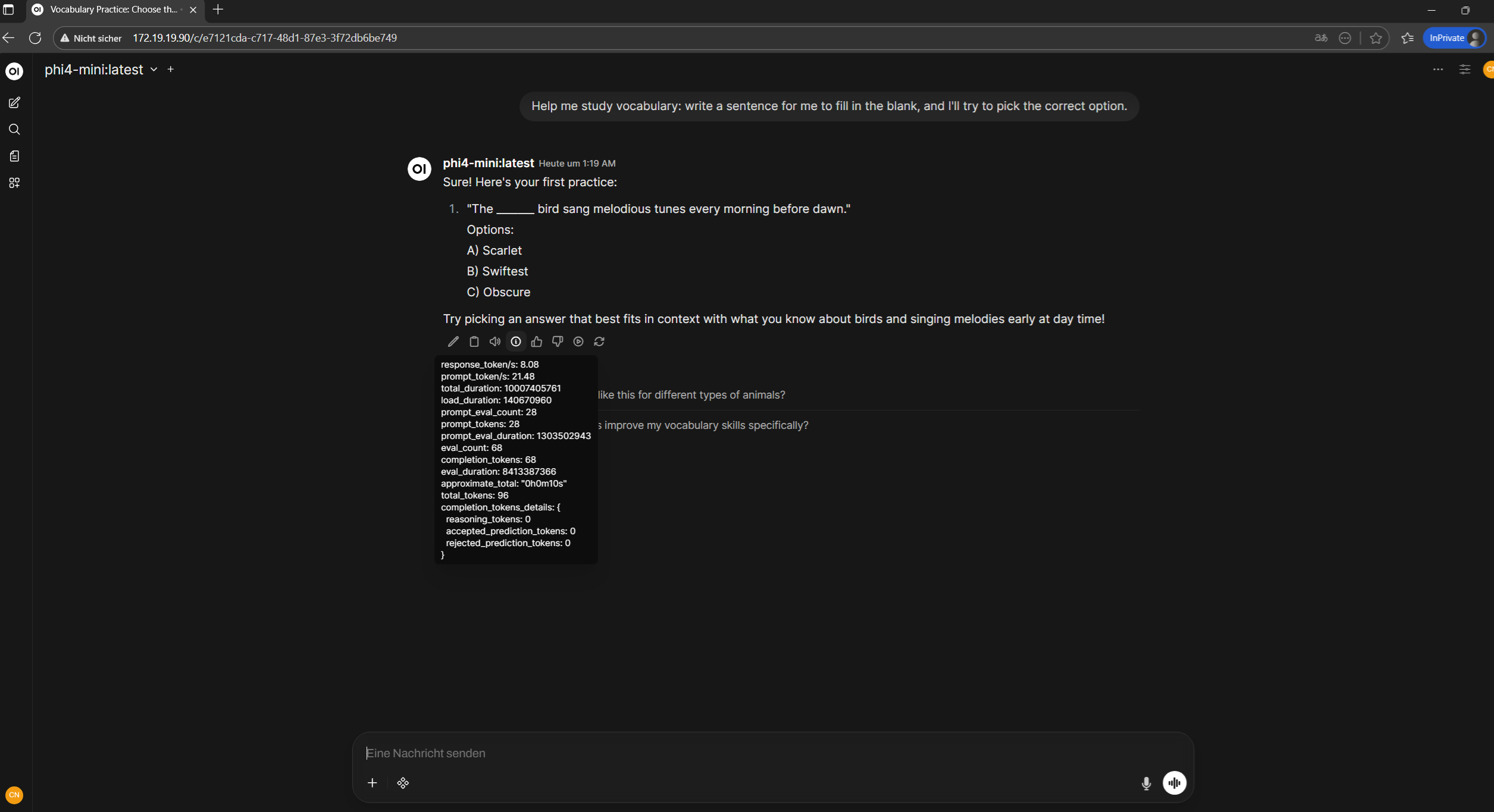
Here are the token-per-second results. Not great, but considering everything is running triple-nested (laptop → Azure Local → AKS) with 4 vCPUs, it’s actually not bad:
With these two deployments you now have:
- A running LLM engine (Ollama) inside the cluster, only accessible internally
- A modern UI (Open WebUI) exposed via MetalLB
- Persistent storage for both models and daily usage
- A clean namespace (
slm) ready for future additions
This stack is a great foundation for experimenting in a hybrid AKS environment, adding observability or even scaling to more nodes.
Conclusion
With this setup you now have a functional environment capable of running lightweight language models inside an AKS cluster on Azure Local. Helm simplifies the deployment of Ollama and Open WebUI and gives you a stable base for further experimentation. Even though this lab runs on limited resources, the approach is perfectly valid for learning more about AKS and understanding how to integrate AI workloads in a hybrid environment.
From here, you can try more models, add observability, integrate GitOps workflows or even move to solutions like KAITO if you get access to a GPU.
Comments